(It really amazes me how much with Unicode was evolved rather than designed.)
| Previous | Top |
|
|
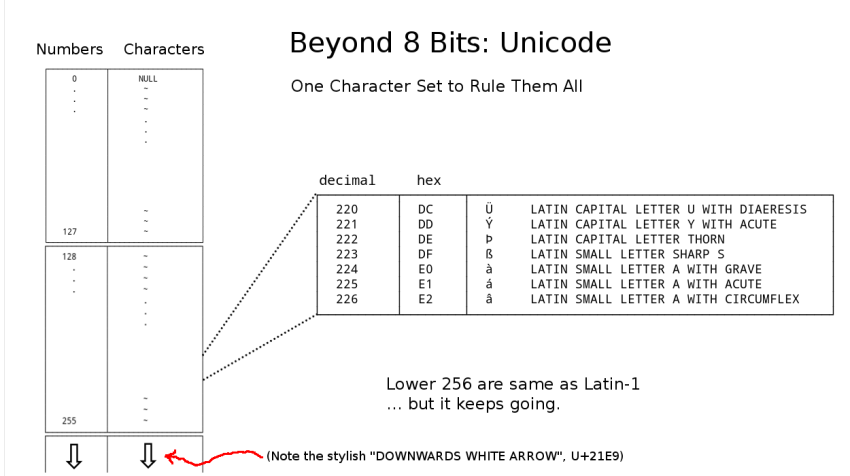
The fact that the lower 256 characters of the Unicode standard
are the same as Latin-1 was certainly convenient (at least for
us Merkin Boobs), but the fact that the lower 128 are the same
as ASCII turned out to be critically useful for UTF-8...
(It really amazes me how much with Unicode was evolved rather than designed.) |
| Next | Top |