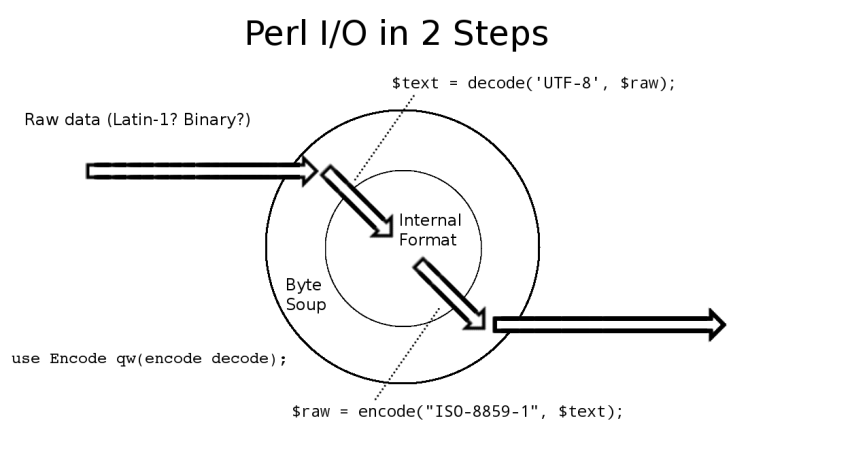
In this example I decided to do Latin-1 output, to make it clear you can use these features with stuff besides UTF-8.
| Previous | Top |
|
|
For some purposes (say you're reading from a db handle that knows
not of UTF-8), this 2-step approach might be useful. You read in
the data, then run it through decode/encode yourself.
In this example I decided to do Latin-1 output, to make it clear you can use these features with stuff besides UTF-8. |
| Next | Top |