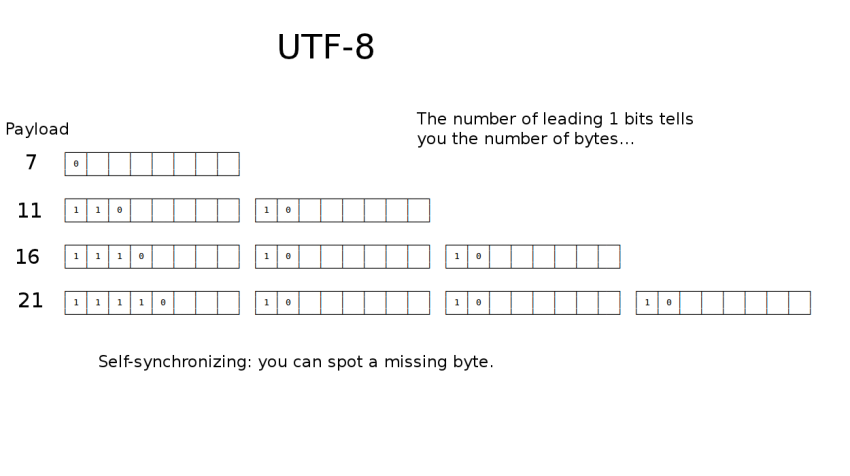
I wanted to make the point that it was "self-synchronizing": if something goes terribly wrong and you lose some information, you can still recover, and find the next character boundary without any trouble.
This used to be a terrible problem with character sets like Shift-Jis in the mid-90s: a C pointer error could shave off one byte and leave you with an entire screen of "mojibake", aka "transformed characters" (or "garbage" to Merkin Boobs like myself).
So, self-synchronization is a great feature.
It also messes everything up--