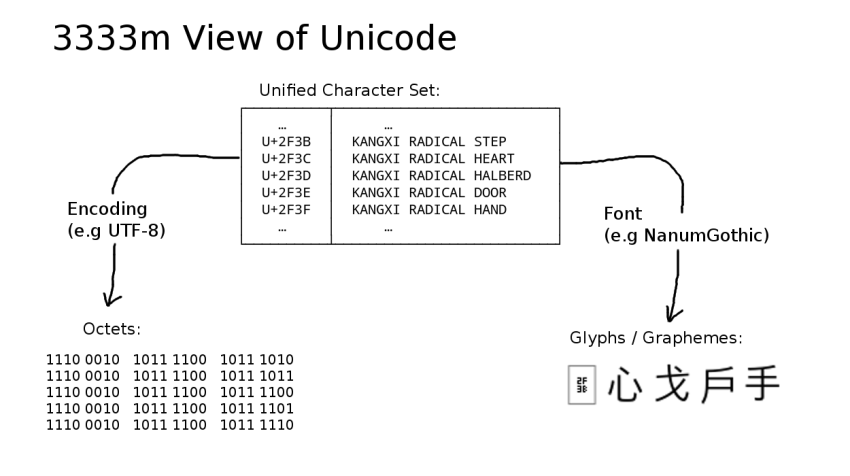
This "ideal" leaks: there are format chracters that tweak appearence, and some codepoints exist just to get some encodings to work.
The character names on the right are abstractions without specific appearence: they need fonts to become "glyphs" which make up "graphemes" (user-readable characters)-- typically there's one glyph per grapheme, but not always.
The codepoint numbers on the left are also abstract, requiring an encoding to turn them into actual "octets" (just like bytes, only cooler-sounding).