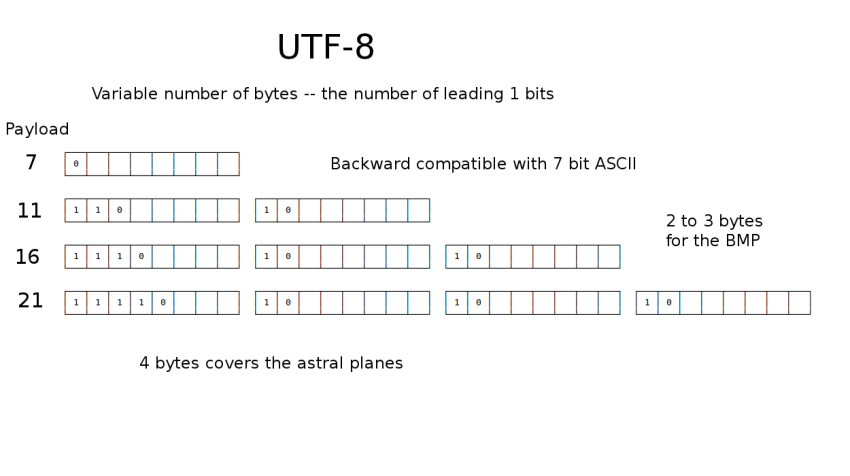
Ken Thompson walked away from UTF-16 and knocked out this scheme, scribbling it on a diner placemat one night.
With UTF-8 every character maps to 1, 2, 3 or 4 bytes. Some bits are dedicated to getting the scheme to work, and the empty spaces shown here are the "payload" available to store useful data.
(In the Disney version of this talk, I would flash a codepoint at the top, and have it explode into a flock of bits that would percolate down and try to find the first available row where they can all fit.)
Some advantages: it's byte-oriented, so there's no BOM. It's completely backwards compatible with ASCII, so NULL-terminated strings can stay that way, file system paths with slash separators still work. And the most frequently used characters will map to fewer bytes.