But there's immense amounts of obscure jargon at work here, e.g. an umlaut is not an umlaut, it's a "DIEARESIS".
Note: the unicode consortium speaks in ascii. Usually upper-case ascii.
| Previous | Top |
|
|
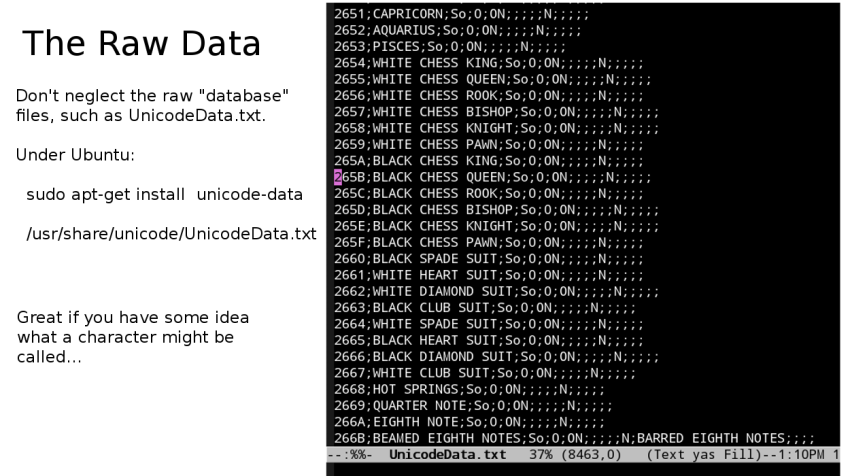
It can be useful to look through the raw Unicode data files directly.
If you have some idea what a character might be called you may be
able to just search for the name to find the codepoint you need.
But there's immense amounts of obscure jargon at work here, e.g. an umlaut is not an umlaut, it's a "DIEARESIS". Note: the unicode consortium speaks in ascii. Usually upper-case ascii. |
| Next | Top |